2021/03/07 - [Book Study/웹 엔지니어가 알아야 할 인프라의 기본] - Chapter 2. 인프라 기술의 기초 지식 -1
2.5 네트워크 보안 이야기
통신의 보안을 유지하기 위해서는 여러 가지 기술이 쓰이지만, 흔히 방화벽과 SSL을 이용하여 네트워크 보안을 유지한다. 방화벽은 안쪽(조직 내부의 네트워크)에서 바깥쪽(인터넷) 또는 바깥쪽에서 안쪽으로의 통신내용을 제어하고, 의도하지 않은 통신이 발생하지 않도록 접속 요구를 차단함으로써 네트워크의 보안을 향상시키는 방법이다. 방화벽에서는 소스 IP주소, 목적지 IP주소, 포트 그리고 접속량 및 통신량을 제한하여 보안을 유지하며, 경우에 따라서 통신 내용까지 검사하기도 한다. 이러한 것을 일괄적으로 대응하는 기기를 UTM(Unified Threat Management), HTTP나 HTTPS 통신의 내부까지 검사하는 기기를 WAF(Web Application Firewall)이라 지칭한다. WAF는 애플리케이션이 예상치 못한 SQL문을 실행시켜 공격하는 SQL 인젝션 방지책으로도 사용된다.
SSL(Secure Sockets Layer)은 통신 암호화를 위해 사용하는데, SSL을 이용하면 사용자가 브라우저에 입력한 개인 정보나 패스워드 등이 안전하게 서버에 도달할 수 있다. 또한 SSL은 계층이기 때문에 HTTP뿐만 아니라 다른 프로토콜과의 조합이 자유로우며, SSL 인증서를 통해 통신 상대의 FQDN을 확인하여 상대방이 진짜 FQDN 관리자임을 증명할 수 있게 된다.
[SSL도 하나의 계층이다]
| 애플리케이션 계층 ~ 세션 계층 |
HTTP |
| SSL | |
| 전송 계층 | TCP |
| 네트워크 계층 | IP |
2.6 인프라 요소의 스펙을 읽는 방법과 선택 방법
서버의 스펙을 구성하는 요소중 가장 중요한 것은 CPU, 메모리, 디스크, 네트워크이다. 프로젝트를 진행할 때에는 예산의 범위 내에서 최대한 저렴한 가격으로 최고의 스펙을 꾸미는 것이 중요하다. 이때, 물리적인 서버는 조달에 시간이 걸리기 때문에 스펙 변경이 어렵지만 클라우드 서비스는 스펙 변경이 간단하므로 스펙을 적절히 변경하여 낭비 없이 운용이 가능하다. 스펙을 결정하기가 어렵다면, 추후 쉽게 수정을 할 수 잇는 클라우드 서비스를 이용하는 것이 좋다. 각 요소들의 스펙과 선택 방법은 아래와 같다.
[CPU, 메모리의 스펙과 선택 방법]
| 소켓 수 | CPU 장착 가능 수량 |
| 코어 수 | CPU당 코어 개수 |
| 스레드 수 | CPU당 스레드 수(Hyper Threading 대응의 CPU에서 카탈로그에 표시된 스레드 수는 코어 개수의 2배가 된다) |
| 동작 주파수 | CPU의 동작 주파수(2.4GHz 등) |
| 버전(세대) | Intel사의 CPU라면 Nehalem, IvyBridge 등 |
| 캐시 메모리 크기 | CPU 내장 메모리의 용량 |
| 최대 메모리 크기 | 장착 가능한 메모리의 최대 크기 |
| 최대 메모리 대역폭 | 장착 가능한 메모리의 최대 대역폭 |
| ECC 메모리 대응 여부 | ECC(오류 정정) 기능이 있는 메모리 대응 여부 |
CPU 내부에는 캐시 메모리가 내장되어있다. 이 캐시 메모리는 CPU 성능에 큰 영향을 미치기 때문에 서버용 CPU는 캐시 메모리의 용량이 큰 것이 특징이다. 추가로 동작 주파수가 높은 CPU는 일괄처리와 같이 병렬도가 낮은 처리를 단시간에 완료하기 위한 용도로 사용하며, 스레드 수가 많은 CPU는 웹 서버와 같이 병렬도가 높은 용도에 사용한다.
[하드디스크의 주요 선정 기준]
| 용량 | 250GB, 500GB, 1TB, 3TB 등 |
| 인터페이스 규격 | SAS 6Gbps/3Gbps, SATA 6Gbps/3Gbps 등 |
| 회전 수 | 15000rpm, 10000rpm, 7200rpm 등 |
| 크기 | 2.5inch, 3.5inch |
디스크는 크게 하드디스크(HDD), SSD, PCI express 인터페이스 플래시 스토리지의 세 종류가 있다. 이러한 디스크는 인터페이스 규격에 따라 최대 통신 속도가 결정되기 때문에 가능한 통신 속도가 더 빠른 규격을 사용하는 것이 좋다. SATA 인터페이스 디스크의 특징은 대용량, 저가격이며, SAS 인터페이스 디스크의 특징은 고성능, 높은 신뢰성(잘 부서지지 않음)이다.
서버 디스크를 결정할 때는 디스크 자체보다 적절한 RAID 카드(RAID 컨트롤러)를 선택하는 것이 중요하다. 실제로 RAID 카드가 OS에서 여러 개의 디스크를 하나의 디스크로 인식하도록 하는 하드웨어 RAID를 통해 데이터의 분산 및 다중화 등을 수행할 수 있게 해 주므로 적절히 사용하는 것이 좋다. OS에서 소프트웨어적으로 RAID를 구성하는 방법도 있지만, 성능을 고려한다면 하드웨어 RAID가 1순위로 고려되어야 한다.
[RAID의 종류와 특징]
| RAID 0 | 디스크를 여러 대 사용하여 전체를 저장 영역으로 한다. 따라서 엑세스 속도의 향상과 OS 측면에서의 디스크 용량 증가를 구현할 수 있다. 하지만 디스크 한 대라도 고장이 발생하면 전체에 문제가 생기므로, 데이터는 잃어도 무관하지만 용량과 엑세스 속도가 필요할 때 이용한다. |
| RAID 1 | 디스크 한 대에 데이터를 저장하고 백업을 준비한다. 엑세스 속도와 용량은 한 대일 때와 같지만, 한대가 고장나도 문제가 없는 다중성이 향상된다. |
| RAID 5 | 데이터로부터 패리티를 생성하여 데이터와 패리티를 함께 여러 대의 디스크에 분산 저장한다. 엑세스 속도의 향상과 디스크 용량이 모두 필요할 때 이용한다. 디스크 한 대까지는 고장이 발생해도 괜찮지만, 한 대가 고장나면 곧바로 수리해야 한다. |
| RAID 6 | 데이터로부터 패리티를 2중으로 생성하여 데이터와 패리티를 함께 여러 대의 디스크에 분산 저장한다. 엑세스 속도의 향상과 디스크 용량이 모두 필요할 때 이용한다. 디스크 두 대까지는 고장이 발생해도 괜찮기 때문에 수리 완료까지는 시간적인 여유가 있다. |
| RAID 10 | RAID 0과 RAID 1을 조합한 것 |
| RAID 50 | RAID 0과 RAID 5을 조합한 것 |
| RAID 60 | RAID 0과 RAID 6을 조합한 것 |
| 종류 | 용량 단가 | 전송 속도 | I/O 속도 |
| HDD | 저렴 | 수백 MB/s 초반 | 100~400 IOPS |
| SSD | 고가 | 수백 MB/s 중반 | 수천~수만 IOPS |
| PCI express 플래시 스토리지 | 매우 고가 | 수백 MB/s 후반 | 수만~수십만 IOPS |
2.7 성능과 데이터에 관한 기초 지식
서비스의 성능 향상을 위해 반드시 고려되어야 하는 것은 'ACID'이다. 이는 메모리 및 파일 조작, 데이터베이스, KVS(Key-Value Store, 데이터 보존 방식의 한 종류) 등 모든 부분에서 고려되어야 하는 항목을 말한다. ACID를 완전히 만족시키고자 하면 서비스 전체의 성능이 감소할 수 있기 때문에 ① 전부를 만족한 채로 성능을 높이는 기술 ② 일부는 만족하지 못하더라도 위험을 감수하며 성능을 높이는 기술이 함께 발전하였다(7/8장에서 설명할 예정).
ACID를 지키기 위해서 발전된 기술 중 락과 배타 처리는 어떤 처리가 리소스를 사용하고 있는 경우에는 다른 처리가 그 리소스를 사용할 수 없도록 하는 것이다. 이는 파일 I/O(입출력)나 DB 조작 등 여러 곳에서 사용되고 있다. 락과 배타 처리를 이용하게 되면 성능이 향상되기 어렵고 병렬도가 높아지는 주요 원인이 생성되지만, 이를 소홀히 하게 되면 데이터의 정합성을 확보할 수 없게 되므로 성능과는 별개로 꼭 필요한 기술이라 할 수 있다.
- Atomicity : 원자성 - 원자성이 부족할 경우, 일련의 처리로써 실행하고자 하는 처리 A와 처리 B에 대해 A 또는 B 중 어느 하나만 실행되는 사태가 발생하여 정확한 처리가 되지 않는다.
- Consistency : 일관성 - 일관성이 없을 경우, 처리 도중의 상태가 노출되어 정확하지 않은 값이 다른 트랜잭션에서 확인이 가능해진다.
- Isolation : 독립성 - 독립성이 없을 경우, 일련의 처리로써 순서대로 실행하고자 하는 처리 1과 처리 2에 대하여 1->2의 순서가 지켜지지 않으며, 다른 트랜잭션에서 처리 중인 내용까지도 볼 수 있게 된다. 독립성이 지켜지는 경우 다른 트랜잭션에서는 '1과 2가 모두 처리되고 있지 않다' 또는 '1과 2가 차례대로 모두 처리되고 있다'라는 상태만 알 수 있게 된다.
- Durability : 지속성 - 지속성이 없을 경우, 처리가 완료되더라도 데이터가 보존되지 않는 사태가 발생한다.
성능을 향상시키기 위해 보틀넥을 제거 또는 완화하기 위한 기술로는 버퍼, 캐시, 큐잉이 있다. 버퍼는 다음 단계의 처리를 효율화하기 위해 데이터를 일시적으로 모아두는 구조로, 데이터를 한 번에 처리하는 것이 효율적인 디스크나 네트워크의 I/O에서 자주 사용된다. 캐시는 연산 결과를 일시적으로 모아두는 방식을 말하며, 쉽게 말해 '결과의 재사용'이라 할 수 있다. 애플리케이션의 처리 결과나 디스크에서 읽은 데이터 취득 결과, 또는 DB에서 읽은 데이터 취득 결과 등을 재사용하게 된다. 큐잉은 처리를 등록하는 방식으로 보틀넥에 의해 서비스 전체 성능이 떨어지는 것을 방지하기 위해 사용된다. 처리를 의뢰하는 곳은 처리 큐에 처리 의뢰를 등록한 후 다음 처리로 넘어갈 수 있게 되며, 이렇게 처리 큐에 등록한 후 결과를 기다리지 않고 다음 처리로 넘어가는 비동기성이 큐잉의 핵심이다.
2.8 다중화의 구조
서비스의 가용성을 높이기 위해 다중화를 한 경우에는, 같은 데이터가 여러 개 존재 가능하다는 점을 주의하여야 한다. 어떤 데이터가 올바른 것인지 또는 가장 최신의 것인지를 제대로 관리하지 못하면 서비스의 신뢰도가 떨어질 수 있기 때문이다. 또한 여러 개의 데이터가 정확하게 일치하고 있는 상태, 즉 데이터의 정합성이 제대로 관리되어야 한다. 일반적으로 데이터의 정합성을 얻기 위해서는 스토리지를 공유하는 Shared Disk 방식과 스토리지를 공유하지 않는 Shared Nothing 방식을 사용한다.
Shared Disk 방식은 하나의 스토리지를 공유하며, 대개는 전용 스토리지 기기를 이용한다. 이러한 방식은 스토리지를 공유하기 때문에 정합성에 대해 특별히 이슈가 발생하지는 않는다. 하지만, Shared Disk 자체를 다중화해야만 전체적인 가용성을 확보할 수 있게 되므로 이 부분에 대한 충분한 검토가 필요하다. Shared Nothing 방식의 경우는 스토리지 간 통신을 통해 데이터 정합성을 확보하는 방식이다. 이것을 리플리케이션(Replication)이라 부르며, 리플리케이션에서 데이터 송신 측은 Master, 데이터 수신 측은 Slave가 된다.

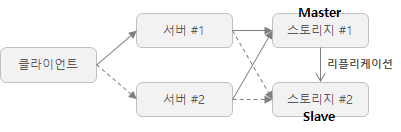
리플리케이션은 오버헤드가 큰(동기 처리에 따른 성능 저하의 정도가 큰) 대신 데이터의 정합성을 확보하기 좋은 동기식 리플리케이션과 과 데이터 손실이 발생할 가능성이 있지만 성능 저하의 정도가 적은 비동기식 리플리케이션 두 가지로 분류된다. 스토리지에 RDBMS(관계 데이터베이스 관리 시스템)를 사용할 경우, MySQL이나 PostgreSQL은 표준으로써 비동기 리플리케이션에 대응하고 있는 것을 알 수 있다. MySQL에서는 5.5 버전부터 준동기식 리플리케이션이라는 명칭으로, PostgreSQL에서는 9.1 버전부터 동기식 리플리케이션이라는 명칭으로 구현되고 있지만 구현하는 기능은 거의 동일하다.

서버의 Active-StandBy 다중화 관계에서 Active 서버에 장애가 발생하여 StandBy서버가 Active로 바뀌는 것을 '승격'이라 하며, 이 과정에서 일어나는 일련의 동작은 페일오버(Failover)라 불린다. 페일오버의 경우 각 벤더에서 제공하는 HA 솔루션을 사용하는 경우가 많으며, 페일오버 솔루션에서는 Master-Slave관계를 Primary-Secondary라 지칭하게 된다. 솔루션을 이용해 페일오버를 하는 경우는 정기적인 모니터링을 통하여 다중화한 상대 쪽의 다운(Down)을 감지해 승격하는 방식이기 때문에 다운 시간이 '0'이 될 수는 없지만, 다운된 후 전환 처리가 개시될 때까지를 수 초 이내로 만들 수 있다.
이러한 솔루션은 가끔 상대 쪽의 다운 상태를 잘못 감지하여 Primary가 다운되지 않은 상태에서도 Secondary를 승격시키고는 하는데, 이와 같은 상태를 Split Brain이라 부르며, Split Brain 상태가 발생하면 데이터의 정합성을 잃게 되는 큰 문제가 발생한다. 따라서 이와 같은 최악의 상태를 방지하기 위해서 Secondary가 승격될 때 Primary를 강제로 정지시키는 STONITH(Shoot The Other Node In The Head)를 이용할 수 있다(STONITH는 Secondray가 승격할 때 Primary의 BIOS에 강제 정지 명령을 내리는 등의 조치로 Split Brain을 방지한다). HA 솔루션을 사용할 때에는 가능한 단순하게 구성하여 전체적인 고장률을 줄이고 복구가 간단하도록 하는 것이 좋다.
2.9 암호화와 해시화
암호화는 복호화(원래대로 되돌릴 수 있다)를 할 수 있다는 것이 특징이며, 이처럼 원래대로 되돌리는 것을 가역이라고 한다. 크게 구분하면 공통키 암호방식, 공개키 암호방식의 두 가지가 있는데, 공통 키 암호방식은 패스워드를 거는 방법이며 공개키 암호방식은 암호화와 복호화에 각각 다른 암호화 키를 준비하여 암호화하는 쪽의 키를 공개하는 방법이다. 한편, 해시는 복호화가 불가능하다는 것이 특징으로, 원래대로 되돌릴 수 없는 불가역 특성을 가지고 있다. 해시에서는 해시화하기 전의 원래 상태를 유추할 수 없지만, 원 데이터가 같다면 반드시 해시도 동일한 값이 된다. 해시화 방식에 따라서 원 데이터가 다른데 동일한 해시값이 되어버리는 충돌이 발생하기도 한다.
해시화는 암호화에 비해 복호화될 걱정은 거의 없는 편이지만, 원래 문자열의 변화가 발생하는 것이기 때문에 해시화 방식이 알려질 경우 짧은 문자열은 해시화 된 목록을 이용해 해독될 가능성이 있다. 이를 피하기 위해서는 특정 변환(길게 하기=salt 넣기)을 진행한 후 해시화 하는 방법을 사용한다. Salt는 해시화 하기 전 원 데이터에 문자열을 추가하는 임의의 데이터를 말한다.
| 패스워드가 'password' 이며, 임의의 Salt 문자열이 '1234'라면 암호화 될 문장은 '1234password1234' 이다. |
'Book Study > 웹 엔지니어가 알아야 할 인프라의 기본' 카테고리의 다른 글
| Chapter 5. 웹 서비스 운용 1 : 시스템 감시의 기본 (0) | 2021.04.04 |
|---|---|
| Chapter 4. 인프라 준비의 기초 지식 (0) | 2021.03.30 |
| Chapter 3. 웹 서비스 서버 구성의 모범 사례 (0) | 2021.03.25 |
| Chapter 2. 인프라 기술의 기초 지식 -1 (0) | 2021.03.07 |
| Chapter 1. 웹서비스에서 인프라의 역할 (0) | 2021.03.03 |